
ปัญญาประดิษฐ์
คำอธิบายประกอบข้อความและสื่อหลายภาษา
ระบบ AI จะฉลาดขึ้นด้วยการประมวลผลข้อมูลแต่ละรอบที่ประสบความสำเร็จ เนื่องจากการทำงานร่วมกันแต่ละครั้งทำให้ระบบสามารถทดสอบ วัดผล และเรียนรู้ได้ เรามองเห็นรูปแบบเดียวกันนี้ในการพัฒนาบริษัทของเรา และนั่นคือเหตุผลว่าทำไมเราจึงมีความหลงใหลในการเรียนรู้ของเครื่องและวิทยาศาสตร์ข้อมูลอย่างน่าทึ่ง
ทางลัดไปยังรายละเอียดคำอธิบายประกอบข้อความและสื่อ



คำอธิบายประกอบข้อความและสื่อ
ชุดย่อยของวิศวกรรมการเรียนรู้ของเครื่องและการวิเคราะห์ข้อมูล

การแนะนำ
คำอธิบายประกอบข้อความและสื่อหรือการติดป้ายกำกับข้อมูลเป็นกระบวนการติดป้ายกำกับองค์ประกอบแต่ละส่วนของข้อมูลการฝึก (ไม่ว่าจะเป็นข้อความ วิดีโอ หรือรูปภาพ) เพื่อช่วยให้เครื่องเข้าใจว่ามีอะไรอยู่ในข้อมูลนั้นอย่างแน่นอน จากนั้นข้อมูลที่มีคำอธิบายประกอบนี้จะถูกนำมาใช้ระหว่างการฝึกโมเดล
ข้อมูลที่มีคำอธิบายประกอบเป็นส่วนสำคัญของโมเดลการเรียนรู้ภายใต้การดูแล เนื่องจากประสิทธิภาพและความแม่นยำของโมเดลดังกล่าวขึ้นอยู่กับคุณภาพและปริมาณของข้อมูลที่มีคำอธิบายประกอบ ข้อมูลที่มีคำอธิบายประกอบมีความสำคัญเพราะว่า
- โมเดลการเรียนรู้ของเครื่องมีแอปพลิเคชันที่สำคัญมากมาย
- การค้นหาข้อมูลที่มีคำอธิบายประกอบคุณภาพสูงเป็นหนึ่งในความท้าทายหลักของการสร้างโมเดลแมชชีนเลิร์นนิง
คำอธิบายประกอบในรายละเอียด
คำอธิบายประกอบข้อความ
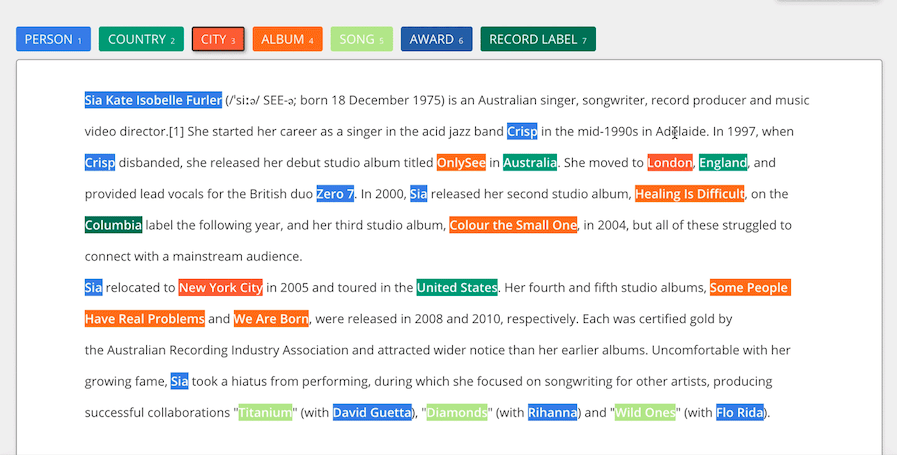
คำอธิบายประกอบข้อความเป็นการต่อท้ายหมายเหตุเข้ากับเนื้อหาต้นฉบับตามเกณฑ์ที่แตกต่างกันซึ่งขึ้นอยู่กับความต้องการของลูกค้า คำอธิบายประกอบข้อความประกอบด้วยขอบเขตที่กว้างขวางขององค์ประกอบต่างๆ เช่น ความรู้สึก เจตนา ความหมาย เอนทิตี หรือความสัมพันธ์
ความรู้สึก
คำอธิบายประกอบเกี่ยวกับความรู้สึกที่ค้นพบอารมณ์และโทนเสียงภายในข้อความโดยติดป้ายกำกับข้อความนั้นว่าเป็นเชิงบวก ลบ หรือเป็นกลาง
เจตนา
คำอธิบายประกอบเจตนาที่รวบรวมความปรารถนาไว้เบื้องหลังข้อความและจำแนกออกเป็นหมวดหมู่ เช่น คำสั่ง คำร้องขอ การยืนยัน เป็นต้น
ความหมาย
คำอธิบายประกอบความหมายที่แท็กข้อความที่อ้างอิงถึงแนวคิดและเอนทิตี เช่น ผู้คน สถานที่ หรือหัวเรื่อง
ความสัมพันธ์
คำอธิบายประกอบความสัมพันธ์ที่แท็กความสัมพันธ์ระหว่างส่วนต่างๆ ของเนื้อหาของคุณ งานต่างๆ รวมถึงการพึ่งพาและการแก้ปัญหาหลัก
องค์กรส่วนใหญ่มองหาผู้อธิบายที่เป็นมนุษย์เพื่อติดป้ายกำกับข้อมูลข้อความ คำอธิบายประกอบที่เป็นมนุษย์มีคุณค่าอย่างยิ่งในการวิเคราะห์ข้อมูลความรู้สึก เนื่องจากข้อมูลนี้สามารถแยกแยะความแตกต่างได้และขึ้นอยู่กับแนวโน้มสมัยใหม่ของคำสแลงและการใช้ภาษาอื่นๆ ในส่วนของแหล่งที่มา REEID GCE ยอมรับทั้งเนื้อหาที่มีโครงสร้างและไม่มีโครงสร้างตลอดจนไฟล์ต้นฉบับที่อยู่ภายใต้ OCR
ตัวอย่างอุตสาหกรรม
ดูแลสุขภาพ
คำอธิบายประกอบข้อมูลข้อความมีบทบาทสำคัญในอุตสาหกรรมการดูแลสุขภาพ โดยเฉพาะอย่างยิ่งในปัจจุบันเมื่อเราจัดการกับบริการที่ใช้ AI ในโดเมนทางการแพทย์ เช่น การจัดการบันทึกของผู้ป่วย แชทบอทด้านการดูแลสุขภาพทางการแพทย์ เป็นต้น
ในกรณีนี้เราไม่สามารถเสี่ยงต่อความไม่ถูกต้องของข้อมูลได้ เนื่องจากเกี่ยวข้องกับชีวิตของผู้ป่วย
ต่อไปนี้เป็นกรณีการใช้งานบางส่วนที่คำอธิบายประกอบแบบข้อความมีบทบาทสำคัญ:
Entity Annotation สำหรับแยกรายละเอียดในรายงานทางการแพทย์ เช่น ข้อมูลตัวเลข เช่น ระดับความดันโลหิต ฮีโมโกลบิน เป็นต้น
- Entity Annotation สำหรับการอธิบายยา ขนาดยา เวลาที่รับประทานยา ฯลฯ จากใบสั่งยาที่แพทย์ให้
- คำอธิบายประกอบเจตนาและคำอธิบายประกอบทางภาษาศาสตร์เพื่อการวิจัยและการศึกษาซึ่งอธิบายรายละเอียดและปมของบริบททำให้ง่ายต่อการอ่านเนื้อหาจำนวนมากได้ง่ายขึ้น
- คำอธิบายประกอบความคิดเห็นเพื่อวัตถุประสงค์ในการตอบกลับในโรงพยาบาล ห้องปฏิบัติการ หรือการใช้งานด้านการดูแลสุขภาพ
- คำอธิบายประกอบเจตนา คำอธิบายประกอบภาษาศาสตร์ และคำอธิบายประกอบเชิงความหมาย สำหรับการบริการลูกค้าในแอปพลิเคชันด้านการดูแลสุขภาพรวมถึงแชทบอท
โลจิสติกส์
อุตสาหกรรมโลจิสติกส์และซัพพลายเชนกำลังขยายตัวอย่างรวดเร็วอย่างรวดเร็ว และการใช้เทคโนโลยีก็เช่นกัน ตั้งแต่การติดฉลากการเรียกเก็บเงินและใบแจ้งหนี้ไปจนถึงผู้ช่วยเสมือน มีข้อมูลขนาดใหญ่ที่สร้างขึ้นทุกวัน
ผู้ช่วยเสมือนฝ่ายดูแลลูกค้าตรวจจับเจตนาโดยการระบุเอนทิตีเฉพาะจากข้อความผู้ใช้
เมื่อลูกค้าเข้าใกล้เพื่อสอบถามอัตรา ผู้ช่วยเสมือนจะถามคำถามสองสามข้อและแจ้งอัตราโดยประมาณทันที เอนทิตีและข้อมูลที่เป็นประโยชน์จะถูกดึงออกมาจากคำตอบ ประมวลผลเพิ่มเติม และระบุอัตราไว้
Data Annotation ในโลจิสติกส์ก็ใช้ดังนี้:
- คำอธิบายประกอบเอนทิตีสำหรับคำอธิบายประกอบชื่อ จำนวนเงิน หมายเลขคำสั่งซื้อ รายการ ฯลฯ จากใบเรียกเก็บเงินและใบแจ้งหนี้
- ความคิดเห็นและคำอธิบายประกอบเอนทิตีสำหรับคำติชมของลูกค้า
การธนาคาร
การธนาคารมีกรณีการใช้งานที่หลากหลาย เนื่องจากในปัจจุบันเราใช้ระบบธนาคารออนไลน์ที่มีการโต้ตอบกับแอปพลิเคชันและเว็บไซต์สำหรับการทำธุรกรรมและบริการอื่น ๆ ที่ได้รับจากธนาคาร
กรณีการใช้งานบางส่วนสำหรับการติดป้ายกำกับข้อมูลในระบบธนาคาร ได้แก่:
- การจัดประเภทข้อความช่วยให้ลูกค้าคาดการณ์การเปลี่ยนใจได้
- ความตั้งใจ ความรู้สึก และคำอธิบายประกอบทางภาษาถูกนำมาใช้สำหรับการบริการลูกค้าและแชทบอท
- – Entity Annotation ใช้สำหรับแยกเอนทิตี เช่น ชื่อ จำนวนเงิน หมายเลขบัญชีธนาคาร ฯลฯ จากแบบฟอร์มประเภทต่างๆ
รัฐบาล
การใช้คำอธิบายประกอบในภาครัฐคล้ายกับการธนาคาร แต่มีขอบเขตกว้างกว่า ภาครัฐ ได้แก่ หน่วยงานการศึกษา การวิจัย อาหารและยา กฎหมาย หน่วยงานภาษี สื่อ ฯลฯ
การใช้คำอธิบายประกอบในโดเมนนี้สรุป:
- เจตนา เอนทิตี และคำอธิบายประกอบทางภาษาสำหรับการบริการลูกค้า แชทบอท และผู้ช่วยเสมือนของส่วนที่กล่าวถึงข้างต้นทั้งหมด
- การจัดหมวดหมู่ข้อความเพื่อจัดหมวดหมู่คดีความทางอาญา แพ่ง ฯลฯ ตามเนื้อหาของคดี
- คำอธิบายประกอบทางภาษาสำหรับตำรวจและสาขาอาชญากรรมเพื่อตรวจจับน้ำเสียง ความหมาย ฯลฯ ของคดีอาญาและคดีและรายงานต่างๆ
- คำอธิบายประกอบเอนทิตีสำหรับเอกสารราชการทั้งหมดที่ใส่คำอธิบายประกอบเอนทิตี เช่น ชื่อ แผนก สถานที่ และวลีสำคัญ
สื่อและข่าว
สื่อและข่าวเป็นอีกภาคส่วนหนึ่งที่มีเนื้อหาที่เป็นข้อความจำนวนมากซึ่งสามารถใช้คำอธิบายประกอบเพื่อทำความเข้าใจเนื้อหาอย่างกว้างขวาง
Data Annotation ในสื่อและข่าวสารมีไว้ในกรณีการใช้งานดังต่อไปนี้:
- Entity Annotation สำหรับใส่คำอธิบายประกอบของเอนทิตีต่างๆ เช่น ชื่อ สถานที่ วลีสำคัญ ตัวเลข ฯลฯ จากบทความต่างๆ
- การจัดหมวดหมู่ข้อความเพื่อจัดหมวดหมู่เนื้อหาเป็นป้ายกำกับต่างๆ สำหรับข่าว เช่น กีฬา การศึกษา หน่วยงานราชการ ในประเทศ ต่างประเทศ บันเทิง เป็นต้น
- คำอธิบายประกอบภาษาศาสตร์และคำอธิบายประกอบความหมายสำหรับคำอธิบายประกอบสัทศาสตร์ ความหมาย และวาทกรรมสำหรับบทความและรายงานข่าว
- นอกเหนือจากกรณีการใช้งานที่กล่าวข้างต้น ยังมีโดเมนย่อยอื่นๆ อีกมากมาย เช่น การวิจัย การศึกษา ความบันเทิง อีคอมเมิร์ซ มัลติมีเดีย เป็นต้น
คำอธิบายประกอบรูปภาพ

Image Annotation คือกระบวนการติดป้ายกำกับส่วนต่างๆ ของรูปภาพเพื่อสอนโมเดล AI หรือ ML ตัวอย่างเช่น โมเดลแมชชีนเลิร์นนิงได้รับความเข้าใจในระดับที่ดี (เช่น มนุษย์) ด้วยการแท็กรูปภาพดิจิทัล และสามารถเข้าใจรูปภาพที่เห็นได้ จำนวนป้ายกำกับในรูปภาพอาจแตกต่างกันไป ขึ้นอยู่กับกรณีการใช้งาน คำอธิบายประกอบรูปภาพมีประเภทพื้นฐานอยู่สองสามประเภทที่อธิบายไว้ด้านล่างนี้
การจำแนกประเภทภาพ
ในขั้นต้น เครื่องจะได้รับการฝึกด้วยรูปภาพที่มีคำอธิบายประกอบ จากนั้นจะกำหนดว่ารูปภาพใดจะแสดงด้วยรูปภาพที่มีคำอธิบายประกอบที่กำหนดไว้ล่วงหน้า
การรับรู้/การตรวจจับวัตถุ
การจำแนกประเภทภาพอีกรูปแบบหนึ่ง เป็นการกำหนดลักษณะที่ถูกต้องของตัวเลขและตำแหน่งเฉพาะของเอนทิตีในภาพ ในขณะที่มีการกำหนดป้ายกำกับให้กับรูปภาพทั้งหมดในการจัดประเภทรูปภาพ เอนทิตีการติดป้ายกำกับการรับรู้วัตถุแยกจากกัน ตัวอย่างเช่น เมื่อจัดหมวดหมู่รูปภาพ รูปภาพจะถูกจัดประเภทเป็นชายหาดหรือป่าไม้ การรู้จำวัตถุจะแท็กเอนทิตีต่างๆ ในรูปภาพทีละรายการ เช่น คน สัตว์ หรือรถยนต์
การแบ่งส่วน
คำอธิบายประกอบรูปภาพในรูปแบบขั้นสูงยิ่งขึ้น เพื่อให้ตีความรูปภาพได้ง่ายขึ้น ระบบจะแบ่งรูปภาพออกเป็นหลายส่วน และส่วนเหล่านี้เรียกว่า วัตถุรูปภาพ การแบ่งส่วนภาพมีสามประเภท:
- การแบ่งส่วนความหมาย: ติดป้ายกำกับวัตถุที่คล้ายกันในภาพตามคุณสมบัติ เช่น ขนาดและตำแหน่ง
- การแบ่งส่วนอินสแตนซ์: สามารถติดป้ายกำกับเอนทิตีแต่ละรายการในรูปภาพได้ โดยจะกำหนดคุณสมบัติของเอนทิตี เช่น ตำแหน่ง และหมายเลข
- การแบ่งส่วนแบบ Panoptic: ทั้งการแบ่งส่วนความหมายและอินสแตนซ์ถูกใช้โดยการรวมเข้าด้วยกัน
คำอธิบายประกอบวิดีโอ
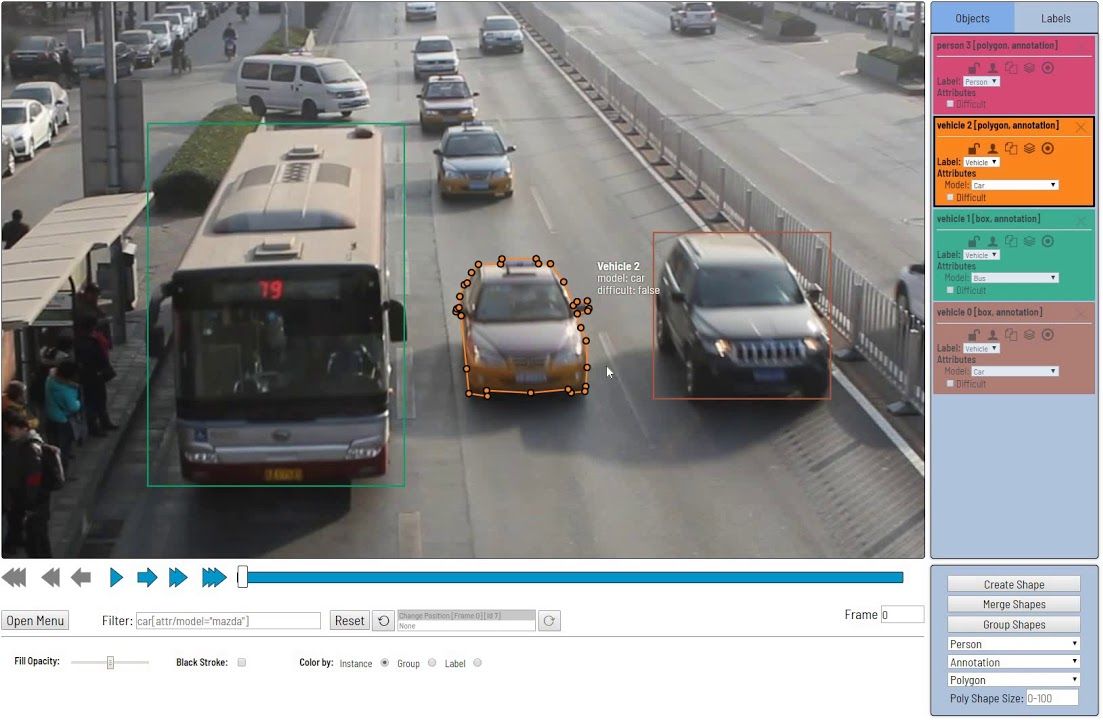
คำอธิบายประกอบวิดีโอเป็นกระบวนการในการแท็กหรือติดป้ายกำกับวิดีโอคลิป สิ่งนี้ถูกนำไปใช้เพื่อเตรียมเป็นชุดข้อมูลสำหรับการฝึกอบรมโมเดลการเรียนรู้ของเครื่อง (ML) และการเรียนรู้เชิงลึก (DL) โครงข่ายประสาทเทียมที่ได้รับการพัฒนาทักษะเหล่านี้จึงถูกนำมาใช้กับแอปพลิเคชันคอมพิวเตอร์วิทัศน์ เช่น เครื่องมือจำแนกวิดีโออัตโนมัติ ช่วยในการตรวจจับและจำแนกวัตถุในวิดีโอของคุณด้วยความแม่นยำแบบเฟรมต่อเฟรม การจดจำวัตถุผ่านคำอธิบายประกอบวิดีโอคอมพิวเตอร์วิทัศน์นั้นคล้ายคลึงกับคำอธิบายประกอบรูปภาพ: คุณสามารถใช้กรอบขอบเขต การแบ่งส่วนความหมาย เส้นหลายเส้น ฯลฯ คุณอาจทราบว่างานที่เกี่ยวข้องกับคำอธิบายประกอบวิดีโอคือการตรวจจับวัตถุที่เคลื่อนไหวในวิดีโอ และทำให้สามารถระบุวัตถุเหล่านั้นได้ภายในโครงร่างของวัตถุแบบเฟรมต่อเฟรมเพื่อให้สามารถฝึกโมเดล AI ได้
ประเภทของคำอธิบายประกอบวิดีโอ
คุณจำเป็นต้องรู้ประเภทของเทคนิคคำอธิบายประกอบวิดีโอ สิ่งนี้จะทำให้เข้าใจข้อกำหนดของคำอธิบายประกอบ
การมาร์ก 2D
คำอธิบายประกอบวิดีโอประเภทนี้ จะมีการใช้กล่องเพื่อทำเครื่องหมายวัตถุในวิดีโอ คำอธิบายประกอบจะวาดกล่องบนเส้นรอบวงของวัตถุ
การมาร์ก 3D
วิธีการนี้ใช้กล่อง 3 มิติเพื่อติดป้ายกำกับวัตถุ ทำให้โมเดล AI สามารถวัดทั้ง 3 มิติของวัตถุได้อย่างแม่นยำ และทำงานร่วมกับวัตถุที่ห่อหุ้มไว้ได้
Polygon Labelling
When the object of concern has an irregular shape, polygon labeling becomes the most precise method.
Landmarks / Keypoints
Keypoint labeling relays on adding points to the objects. ซึ่งมีประสิทธิภาพในการจับภาพการเคลื่อนไหวของการแสดงออกทางสีหน้า ส่วนของร่างกาย ยานพาหนะ เครื่องมือ และวัตถุโครงกระดูกที่กำลังเคลื่อนไหวอื่นๆ
เส้นและเส้นโค้ง: หนึ่งในวัตถุประสงค์หลักของเส้นและเส้นโค้งคือการกำหนดเลนและขอบเขตของพื้นที่ที่นิยมใช้ในระบบยานยนต์อัตโนมัติ
มาตรการรักษาความปลอดภัยของข้อมูล
เราดูแลข้อมูลและทรัพยากรของคุณเป็นพิเศษ เราเข้าใจดีว่าเอกสารและข้อมูลบางอย่างของคุณจะต้องเก็บไว้ให้พ้นจากการเข้าถึงของบุคคลที่ไม่มีสิทธิพิเศษ และ/หรือบอท ต่อไปนี้เป็นการควบคุมความปลอดภัยและวิธีการปรับใช้ในหน่วยธุรกิจของเรา:
- เราไม่ใช้บริการจัดเก็บข้อมูลบนคลาวด์ (Google, Dropbox ฯลฯ) สำหรับข้อมูลที่ละเอียดอ่อน (เว้นแต่ลูกค้าจะระบุไว้เป็นอย่างอื่น)
- เราไม่ใช้ SMT (เครื่องมือแปลเครื่องทางสถิติ) จากภายนอก เว้นแต่ลูกค้าจะระบุไว้เป็นอย่างอื่น
- เราไม่สร้าง ฝึกอบรม และปรับใช้ระบบ Machine Learning และประมวลผลชุดข้อมูลโดยใช้กลไกของบุคคลที่สามบนระบบคลาวด์ เว้นแต่ลูกค้าจะระบุไว้เป็นอย่างอื่น
- เราใช้โปรโตคอลการส่งข้อมูลที่ปลอดภัยสำหรับการสื่อสารภายนอกเท่านั้น
- การเข้ารหัสไฟล์ที่แข็งแกร่งภายในที่จัดเก็บในเครื่องและ DMS แบบกระจาย
- สิทธิพิเศษในการเข้าถึงแพลตฟอร์มออนไลน์ของเรา (โปรไฟล์ บทบาท กฎการแบ่งปัน)
- การควบคุมการเข้าถึงระดับบันทึกฐานข้อมูล
- การตรวจสอบสิทธิ์ MFA สำหรับการเข้าถึงข้อมูลที่ละเอียดอ่อนทั้งหมด
- มีขั้นตอนการทำลายและกำจัดข้อมูล
- ระบบป้องกันการบุกรุก
- มีระบบและขั้นตอนการป้องกันข้อมูลสูญหาย (DLP) แบบหลายชั้น
- ขั้นตอนการลบข้อมูลระบุตัวตน (สำคัญในขณะที่จ้างโครงการ)
- การตรวจสอบความปลอดภัยและการรักษาความลับเป็นประจำ
- ศูนย์ข้อมูลในยุโรปและเอเชีย (ขึ้นอยู่กับข้อกำหนดด้านความปลอดภัยของข้อมูล เลือก DC บางแห่ง)
- การปฏิบัติตาม GDPR เต็มรูปแบบ
- การปฏิบัติตามข้อกำหนดด้านการปกป้องข้อมูลตามกฎระเบียบของประเทศนอกเขตยูโรโซน