
ARTIFICIAL INTELLIGENCE
Multilingual Text and Media Annotation
AI systems get smarter with each successful round of information processing, since each synergy allows the system to test, measure, and learn. We can see the same pattern in our company development, and that’s why we have a remarkable passion for Machine Learning and Data Science
Shortcuts to the Text and Media Annotation details



Text and Media Annotation
Subset of Machine Learning & Data Analysis Engineering

Introduction
Text and Media Annotation or data labeling is the process of labeling individual elements of training data (whether text, video, or images) to help machines understand what exactly is in that data. This annotated data is then applied during model training.
Annotated data is the lifeblood of supervised learning models since the performance and accuracy of such models depend on the quality and quantity of annotated data. Annotated data matters because
- Machine learning models have a wide variety of critical applications
- Finding high-quality annotated data is one of the primary challenges of building machine learning models
Annotation in Details
TEXT ANNOTATION
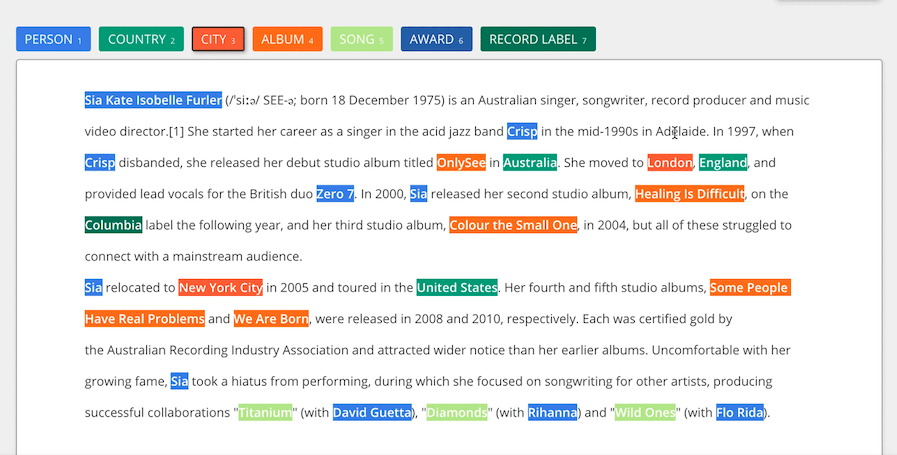
Text Annotation is appending remarks to the source content based on different criteria which are depending on the client requirements. Annotations of text consists a wide scope of various elements, such as sentiment, intent, semantic, entity or relationship
Sentiment
Sentiment annotation discovering emotions and tonality within a text by labeling that text as positive, negative, or neutral
Intent
Intent annotation capturing desire behind a text and classifying it into categories, such as command, request, confirmation etc.
Semantic
Semantic annotation tagging a text that referencing concepts and entities, such as people, places, or subjects.
Relationship
Relationship annotation tagging relationships between different parts of your content. Tasks include dependency and coreference resolution.
Most organizations seek out human annotators to label text data. Human annotators are especially valuable in analyzing sentiment data, as this can often be nuanced and is dependent on modern trends in slang and other uses of language. Regarding source, REEID GCE accepting both structured and unstructured content as well as source files which are subject to OCR.
Example of Industries
Healthcare
Text data Annotation plays an important role in healthcare industry, especially today when we deal with AI-based services in the medical domain such as patients’ records management, medical healthcare chatbots, etc.
In this case we can not risk data inaccuracy, as it is concerned with the patient’s life.
Here are some use cases where text annotation plays a vital role:
Entity Annotation for extracting details in the medical reports such as the numerical data such as blood pressure level, hemoglobin, etc.
- Entity Annotation for annotating medicines, dose, time of intaking medicine, etc. from the prescription given by the doctor.
- Intent Annotation and linguistics annotation for research and study purpose which annotates details and crux of the context making it easier to go through the large volume of the content.
- Sentiment Annotation for the feedback purpose in any hospital, laboratory, or healthcare applications.
- Intent Annotation, Linguistics Annotation, and Semantic Annotation for the customer service in the healthcare applications as well as the chatbots.
Logistics
The logistics and Supply Chain industry is expanding in speedy peace and so is the use of technology in it. From billing and invoice labeling to virtual assistants, there is a large data generated every day.
Customer Care Virtual Assistant detect intent by identifying a particular entity from the user message.
When the customer approaches for a rate inquiry, the virtual assistant asks a few questions and immediately provides the approximate rate. The entities and the useful information are extracted from the responses, processed further and the rates are provided.
Data Annotation in logistics is also used as follows:
- Entity annotation for annotation of the names, amounts, order no, items, etc. from the bills and invoices.
- Sentiment and Entity Annotation for the customer feedback.
Banking
Banking has an extensive range of use cases as nowadays, we use online banking that includes interacting with the applications and websites for transactions and other services given by the bank
Some use cases for data labeling in banking include:
- Text Classification helps customer churn prediction
- Intent, sentiment, and linguistic annotation are used for customer services and chatbots.
- – Entity Annotation is utilized for extracting entities such as name, amount, bank account no., etc. from various types of forms.
Government
The use of annotation in the government sector is similar to banking but has a broader spectrum. The government sector includes the education departments, research, food and drugs, legal, tax departments, media, etc.
The use of annotation in this domain encapsulates:
- The intent, entity, and linguistic annotation for all the above-discussed sector’s customer service, chatbots, and virtual assistants.
- Text classification for categorizing legal cases in criminal, civil, etc. based on the content of the cases.
- Linguistic Annotation for police and crime branch for detecting tones, semantics, etc. of the criminal and various cases and reports.
- Entity Annotation for all the government documents annotating the entities such as names, department, location, and key phrases.
Media and News
Media and News is another sector having a lot of textual content where the Annotation can be widely used to understand the content.
Data Annotation in media and news are in the following use cases:
- Entity annotation for annotation of various entities such as names, location, key phrases, numbers, etc. from various articles.
- Text Classification for categorizing the content into various labels for news such as sports, education, government, domestic, international, entertainment, etc.
- Linguistic Annotation and Semantic Annotation for annotation of the phonetics, semantics, and discourse for the articles and news reports.
- Apart from the use cases mentioned above, there are various other subdomains such as Research, Education, Entertainment, E-Commerce, Multimedia, etc.
IMAGE ANNOTATION

Image Annotation is the process of labeling sectors of images to teach an AI or ML model. For example, a machine learning model gains a great level of comprehension (like a human) with tagged digital pictures and can understand the images it sees. Depending on the use case, the number of labels in the image may vary. There are a few fundamental types of image annotation described below.
Image Classification
Initially, the machine is trained with annotated images, next determines what an image displays with the pre-defined annotated images.
Object Recognition/Detection
A further form of image classification. It is the correct characterization of the numbers and specific positions of entities in the image. While a label is assigned to the entire image in image classification, object recognition labeling entities separately. For example, with image classification, the image is classified as a beach or forest. Object recognition individually tags various entities in an image, such as a human, animal, or car.
Segmentation
A more advanced form of image annotation. In order to interpret the image easier, it breaks down the image into multiple sections and these parts are called image objects. There are three types of image segmentation:
- Semantic segmentation: Label similar objects in the image according to their properties, such as their size and location.
- Instance segmentation: Each entity in the image can be labeled. It defines the properties of entities, such as position and number.
- Panoptic segmentation: Both semantic and instance segmentations are used by combining them.
VIDEO ANNOTATION
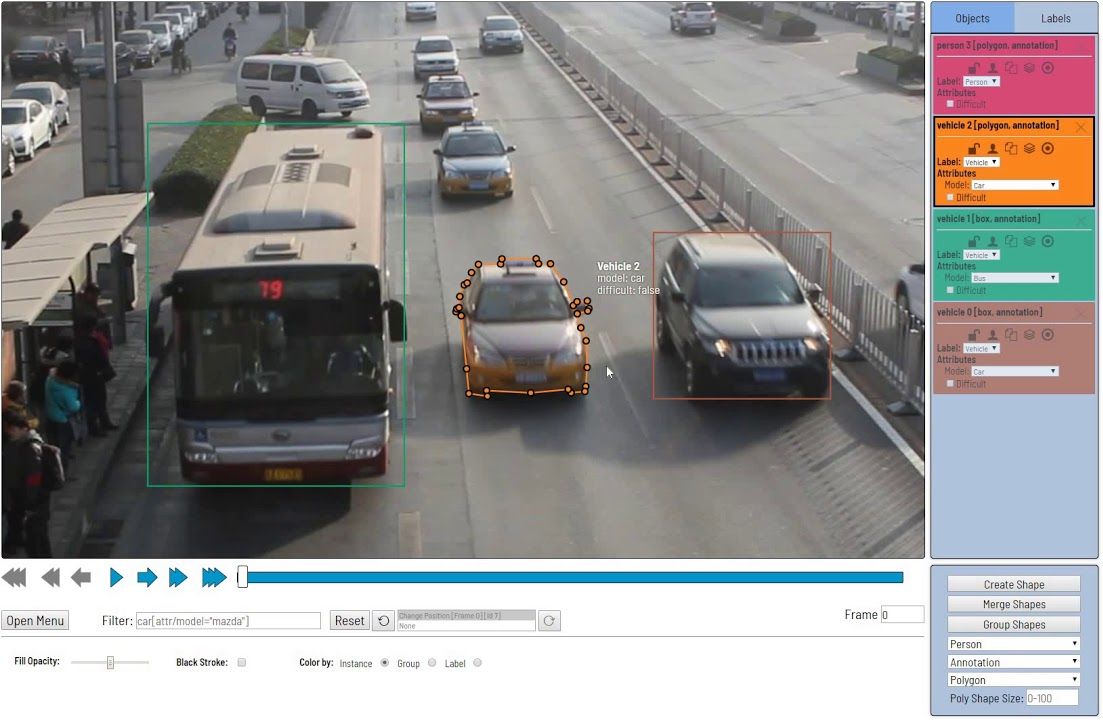
Video annotation is the process of tagging or labelling video clips. This is carried to prepare it as a dataset for training machine learning (ML) and deep learning (DL) models. These upskilled neural networks are thus used for computer vision applications, such as automatic video classification tools. It helps in detecting and classifying objects in your video with precision frame-by-frame. Recognition of the objects through computer vision video annotation is similar to image annotation: you can use bounding box, semantic segmentation, polyline, etc. You might perhaps be aware that the task involved in video annotation is to detect the moving objects in videos and make them identifiable within frame-to-frame outlining of objects to be able to train AI models.
Types of Video Annotation
It is necessary you need to know the types of video annotation techniques. This will give an understanding of annotation requirements.
2D Marking
This type of video annotation, a boxes are used to mark objects in the videos. Annotators draw boxes on the perimeter of the objects.
3D Marking
This method uses 3D boxes to label the objects, allowing the AI model to precisely measure all 3 dimensions of the object and its synergy with enveloping objects.
Polygon Labelling
When the object of concern has an irregular shape, polygon labeling becomes the most precise method.
Landmarks / Keypoints
Keypoint labeling relays on adding points to the objects. This is effective in capturing the movement of facial expressions, body parts, vehicles, instruments and other moving skeletal objects.
Lines & Splines: One of the main purposes of lines and splines is to determine lanes and boundaries of an area that are popularly used in autonomous vehicle systems.
DATA SECURITY MEASURES
We prioritize the security of your data and our resources with exceptional diligence. Recognizing the need to protect certain documents and information from unprivileged individuals and automated systems, we have implemented rigorous safety controls and methodologies across our business units:
- We don’t use cloud based storage services (Google, Dropbox etc.) for sensitive data ( unless specified otherwise by Customer)
- We don’t use outsourced SMT (Statistical Machine Translation Engines) unless specified otherwise by Customer
- We don’t Build, Train, and Deploy Machine Learning systems and process datasets with use of cloud based third parties engines unless specified otherwise by Customer
- We are using only secured transmission protocols for external communication
- Strong files encryption within local storages and Distributed DMS
- Robust access privileges to our online platforms (profiles, roles, sharing rules)
- Access control on databases records level
- MFA authentication for all access to sensitive data
- Data destruction and disposal procedure in place
- Intrusion prevention system
- Multilayer data loss prevention (DLP) systems and procedures in place
- Data anonymization procedures (important while outsourcing projects)
- Regular Security & Confidentiality Audits
- Data Centers in Europe and Asia (depending on data security requirements, certain DC is selected)
- Full GDPR compliance
- Data protection compliance in line with regulations of the countries out of Euro-zone