




人工知能
多言語テキストおよびメディア注釈
AIシステムは、情報処理が成功するたびに賢くなる。各相乗効果によって、システムはテストし、測定し、学習することができるからだ。 私たちの会社の発展にも同じパターンが見られ、だからこそ私たちは機械学習とデータ・サイエンスに並々ならぬ情熱を注いでいるのだ。
テキストとメディア注釈の詳細へのショートカット



テキストとメディア注釈
機械学習・データ分析エンジニアリングのサブセット

はじめに
テキストとメディア アノテーションまたはデータラベリングは、学習データ(テキスト、ビデオ、画像など)の個々の要素にラベルを付けるプロセスであり、機械がそのデータに含まれる内容を正確に理解できるようにする。 このアノテーションされたデータは、モデルの学習時に適用される。
教師あり学習モデルの性能と精度は、注釈付きデータの質と量に依存するため、注釈付きデータは教師あり学習モデルの生命線である。 注釈付きデータが重要なのは
- 機械学習モデルの重要な用途は多岐にわたる。
- 高品質なアノテーションデータを見つけることは、機械学習モデルを構築する際の主要な課題の1つである。
アノテーションの詳細
テキスト注釈
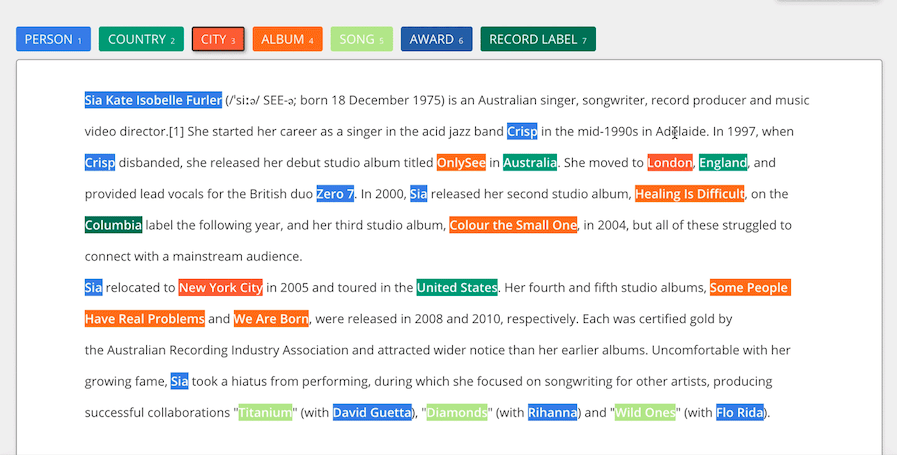
テキストアノテーションは、クライアントの要件に依存するさまざまな基準に基づいて、ソースコンテンツに備考を追加します。 テキストの注釈は、感情、意図、意味、実体、関係などの様々な要素から構成される。
センチメント
センチメントアノテーションは、テキストにポジティブ、ネガティブ、ニュートラルのラベルを付けることで、テキスト内の感情やトーン性を発見する。
意図
テキストの背後にある欲求をとらえ、命令、要求、確認などのカテゴリーに分類するインテント注釈。
セマンティック
人、場所、主題などの概念や実体を参照するテキストにタグを付ける意味的注釈。
人間関係
コンテンツの異なる部分間の関係をタグ付けする関係注釈。 タスクには、依存関係と共参照の解決が含まれる。
ほとんどの組織は、テキストデータにラベルを付けるために人間のアノテーターを求めている。 人間のアノテーターは、センチメントデータを分析する上で特に貴重である。 ソースに関しては、REEID GCEは構造化されたコンテンツと構造化されていないコンテンツの両方を受け入れ、OCRの対象となるソースファイルも受け入れる。
産業例
ヘルスケア
テキストデータのアノテーションは、ヘルスケア産業において重要な役割を果たしている。特に今日、患者の記録管理、医療ヘルスケアチャットボットなど、医療領域におけるAIベースのサービスを扱う際に重要な役割を果たす。
この場合、患者の命に関わることなので、データが不正確になるリスクを冒すことはできない。
テキスト注釈が重要な役割を果たす使用例をいくつか紹介しよう:
血圧値やヘモグロビンなどの数値データなど、医療報告書の詳細を抽出するためのエンティティアノテーション。
- 医師が出した処方箋から、薬、服用量、服用時間などを注釈するためのエンティティ注釈。
- 研究・調査目的のためのインテンション・アノテーションと言語学的アノテーションは、コンテクストの詳細と核心を注釈することで、大量のコンテンツに目を通すことを容易にします。
- センチメント・アノテーションは、病院、研究室、またはヘルスケア・アプリケーションにおけるフィードバックの目的で使用されます。
- チャットボットだけでなく、ヘルスケアアプリケーションの顧客サービスのためのインテント注釈、言語学的注釈、およびセマンティック注釈。
物流
ロジスティクスとサプライチェーン業界は急速に拡大しており、テクノロジーの活用も進んでいる。 請求書やインボイスのラベリングからバーチャルアシスタントまで、毎日大量のデータが生成されている。
カスタマーケア・バーチャルアシスタントは、ユーザーメッセージから特定のエンティティを識別することで、意図を検出します。
顧客が料金の問い合わせをすると、バーチャルアシスタントはいくつかの質問をし、すぐにおおよその料金を提示する。 エンティティや有用な情報が回答から抽出され、さらに処理され、レートが提供される。
また、ロジスティクスにおけるデータ・アノテーションは以下のように使用される:
- 請求書やインボイスから名前、金額、注文番号、品目などを注釈するためのエンティティ注釈。
- 顧客フィードバックのセンチメントとエンティティ注釈。
バンキング
今日、私たちはオンライン・バンキングを利用しているが、これには銀行が提供する取引やその他のサービスのためのアプリケーションやウェブサイトとのやり取りが含まれる。
銀行におけるデータ・ラベリングの使用例には、以下のようなものがある:
- テキスト分類は顧客離れの予測に役立つ
- インテント、センチメント、言語アノテーションは、顧客サービスやチャットボットに使用されます。
- – エンティティ・アノテーションは、様々な種類のフォームから名前、金額、銀行口座番号などのエンティティを抽出するために利用される。
政府
政府部門におけるアノテーションの使用は、銀行業務と似ているが、その範囲はより広い。 政府部門には、教育部門、研究部門、食品・薬品部門、法務部門、税務部門、メディアなどが含まれる。
この領域でのアノテーションの使用は、カプセル化される:
- 上記のすべての分野のカスタマーサービス、チャットボット、バーチャルアシスタントに対する意図、エンティティ、言語アノテーション。
- 刑事事件、民事事件など、事件の内容に応じて分類するためのテキスト分類。
- 警察や犯罪課のための言語アノテーションで、犯罪や様々な事件、報告書の語調、意味などを検出します。
- 名前、部署、場所、キーフレーズなどのエンティティを注釈するすべての政府文書のためのエンティティ注釈。
メディアとニュース
メディアとニュースもまた、多くのテキストコンテンツを持つ分野であり、アノテーションはコンテンツを理解するために広く利用できる。
メディアやニュースにおけるデータ・アノテーションは、以下のような使用例がある:
- 様々な記事から名前、場所、キーフレーズ、数字などの様々なエンティティをアノテーションするためのエンティティアノテーション。
- スポーツ、教育、政府、国内、国際、娯楽など、ニュースのさまざまなラベルにコンテンツを分類するためのテキスト分類。
- 言語学的アノテーションと意味論的アノテーションは、記事と報道の音声学、意味論、談話のアノテーションを行う。
- 上記のユースケース以外にも、リサーチ、教育、エンターテインメント、Eコマース、マルチメディアなど、さまざまなサブドメインがある。
画像注釈

画像アノテーションは、AIやMLモデルに教えるために画像のセクターにラベルを付けるプロセスである。 例えば、機械学習モデルは、タグ付けされたデジタル写真に対して(人間のように)大きな理解力を獲得し、見た画像を理解することができる。 ユースケースによって、画像内のラベルの数は異なる場合がある。 画像注釈にはいくつかの基本的な種類があります。
画像分類
最初に、機械は注釈付き画像で訓練され、次に、あらかじめ定義された注釈付き画像で画像が何を表示するかを決定する。
物体認識/検出
画像分類のさらなる形態。 これは、画像内のエンティティの数と特定の位置を正しく特徴付けることである。 画像分類では画像全体にラベルが割り当てられるが、物体認識では実体を個別にラベリングする。 例えば、画像分類では、画像はビーチか森かに分類される。 物体認識は、人間、動物、車など、画像内のさまざまな実体を個別にタグ付けする。
セグメンテーション
より高度な画像注釈。 画像を解釈しやすくするために、画像を複数のセクションに分解し、これらの部分を画像オブジェクトと呼ぶ。 画像分割には3つのタイプがある:
- 意味的セグメンテーション:画像内の類似オブジェクトに、そのサイズや位置などの特性に従ってラベルを付ける。
- インスタンスのセグメンテーション:画像内の各エンティティにラベルを付けることができる。 位置や数など、エンティティのプロパティを定義する。
- パノプティック・セグメンテーション: セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせて使用する。
ビデオ注釈
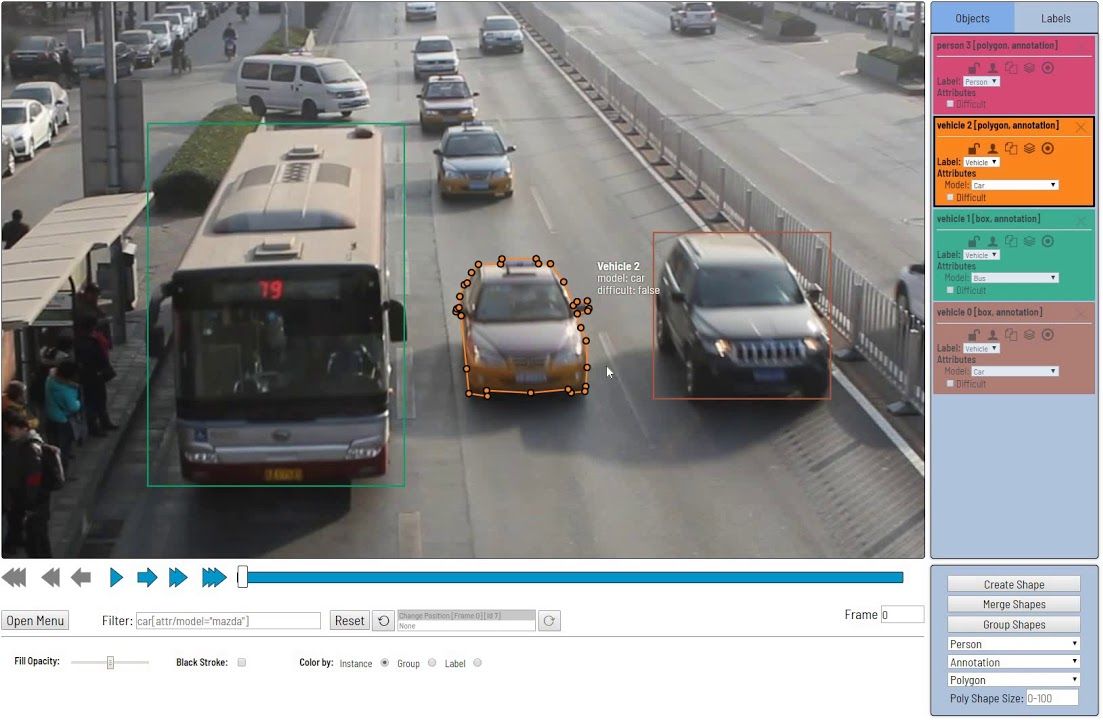
ビデオアノテーションとは、ビデオクリップにタグを付けたり、ラベルを付けたりすることである。 これは、機械学習(ML)や深層学習(DL)モデルを学習するためのデータセットとして準備するために行われる。 このように熟練したニューラルネットワークは、自動ビデオ分類ツールなどのコンピュータビジョンアプリケーションに使用される。 フレームごとに正確にビデオ内のオブジェクトを検出し、分類するのに役立ちます。 コンピュータビジョンのビデオアノテーションによるオブジェクトの認識は、画像アノテーションに似ています:バウンディングボックス、セマンティックセグメンテーション、ポリラインなどを使用することができます。 動画アノテーションのタスクは、動画内の動くオブジェクトを検出し、AIモデルを学習できるように、オブジェクトのフレーム間アウトラインで識別できるようにすることであることはご存知かもしれない。
ビデオアノテーションの種類
ビデオ注釈技術の種類を知っておく必要がある。 これにより、アノテーションの要件を理解することができる。
2D Marking
このタイプのビデオアノテーションでは、ビデオ内のオブジェクトをマークするためにボックスが使用されます。 アノテーターはオブジェクトの外周にボックスを描く。
3Dマーキング
この方法では、3Dボックスを使ってオブジェクトにラベルを付け、AIモデルがオブジェクトの3次元すべてと、それを取り囲むオブジェクトとの相乗効果を正確に測定できるようにする。
ポリゴンラベリング
対象物の形状が不規則な場合、ポリゴンラベリングが最も正確な方法となる。
Landmarks / Keypoints
Keypoint labeling relays on adding points to object. これは、顔の表情、体の一部、乗り物、楽器、その他の動く骨格オブジェクトの動きをキャプチャするのに有効です。
線とスプライン: 線とスプラインの主な目的の1つは、自律走行システムでよく使われる車線と領域の境界を決定することです。
情報およびデータのセキュリティ
私たちは、お客様のデータと私たちのリソースのセキュリティを最優先し、細心の注意を払っています。 権限のない個人や自動化システムから特定の文書や情報を保護する必要性を認識し、当社は事業部門全体で厳格な安全管理と方法論を導入しています:
- 当社は、クラウドベースのストレージサービス(Google、Dropboxなど)を機密データ用に使用しません(お客様が別途指定した場合を除く)。
- お客様の指定がない限り、外注のSMT(統計的機械翻訳エンジン)は使用しません。
- 当社は、お客様が特に指定しない限り、機械学習システムの構築、トレーニング、およびデプロイを行わず、クラウドベースのサードパーティエンジンを使用してデータセットを処理します。
- 外部との通信には、安全な通信プロトコルのみを使用しています。
- ローカル・ストレージおよび分散DMS内の強力なファイル暗号化
- オンラインプラットフォームへの強固なアクセス権限(プロファイル、ロール、共有ルール)
- データベースのレコードレベルでのアクセス制御
- 機密データへのすべてのアクセスに対するMFA認証
- データ破棄・廃棄手順
- 侵入防止システム
- 多層的なデータ損失防止(DLP)システムと手順の導入
- データの匿名化手順(プロジェクトをアウトソーシングする際に重要)
- 定期的なセキュリティと機密性の監査
- ヨーロッパとアジアのデータセンター(データセキュリティの要件に応じて、特定のDCが選択される)
- GDPRに 完全準拠
- ユーロ圏外の国々の規制に沿ったデータ保護コンプライアンス